A Rough Guide to Dashboard Actions



Editor's Note: This is a repost of an article by Peter Gilks on his blog, Paint by Numbers.
As you probably can tell by now, I really enjoying building data visualisations in Tableau. Whether for this blog or for work, I strive to build dashboards that people will be able to use to explore the data at their own pace and discover their own insights.
One way I attempt to do this is by using, what I hope is, engaging visual design. The other is by building in interactive features into the dashboard that people can play with to start changing the views of the data. This is accomplished in three primary ways: Quick Filters, Parameters and Dashboard Actions. Of these three Dashboard Actions have become my favourite as they are probably the most flexible and offer the most immersive experience. So here's my rough guide to Tableau Dashboard Actions. Its not completely exhaustive, and its not particularly technical, but if you are fairly new to Tableau, or even an experienced user, I hope you will find it a useful guide.
What is a Dashboard Action?
A dashboard action is an interactive element on a Tableau dashboard that is driven from the worksheets within that dashboard. There are three types of dashboard action:
- Filter
- Highlight
- URL
Tableau themselves provide a good run down of how to build in Dashboard Actions here http://onlinehelp.tableausoftware.com/current/pro/online/mac/en-us/actions.html. So rather than repeat what Tableau have already documented, I am going to show a variety of use cases for using Dashboard Actions and how to implement them. Those use cases are:
Use Case 1: Basic Chart to Chart Filtering
Use Case 2: Pre-Filtering a Large Table
Use Case 3: Creating a 'Cross-Blend' Filter
Use Case 4: Showing Images
Use Case 5: Dynamic Text or Titles
Use Case 6: Linking Out to Web Pages
Use Case 7: Highlighting and Labelling
Use Case 8: Switching Dashboards
Use Case 9: Mixing Things Up
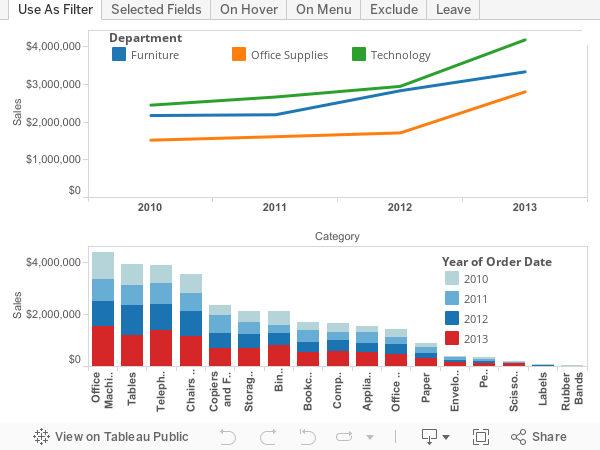
Use Case 1: Basic Chart to Chart Filtering
Method 1: Use As Filter
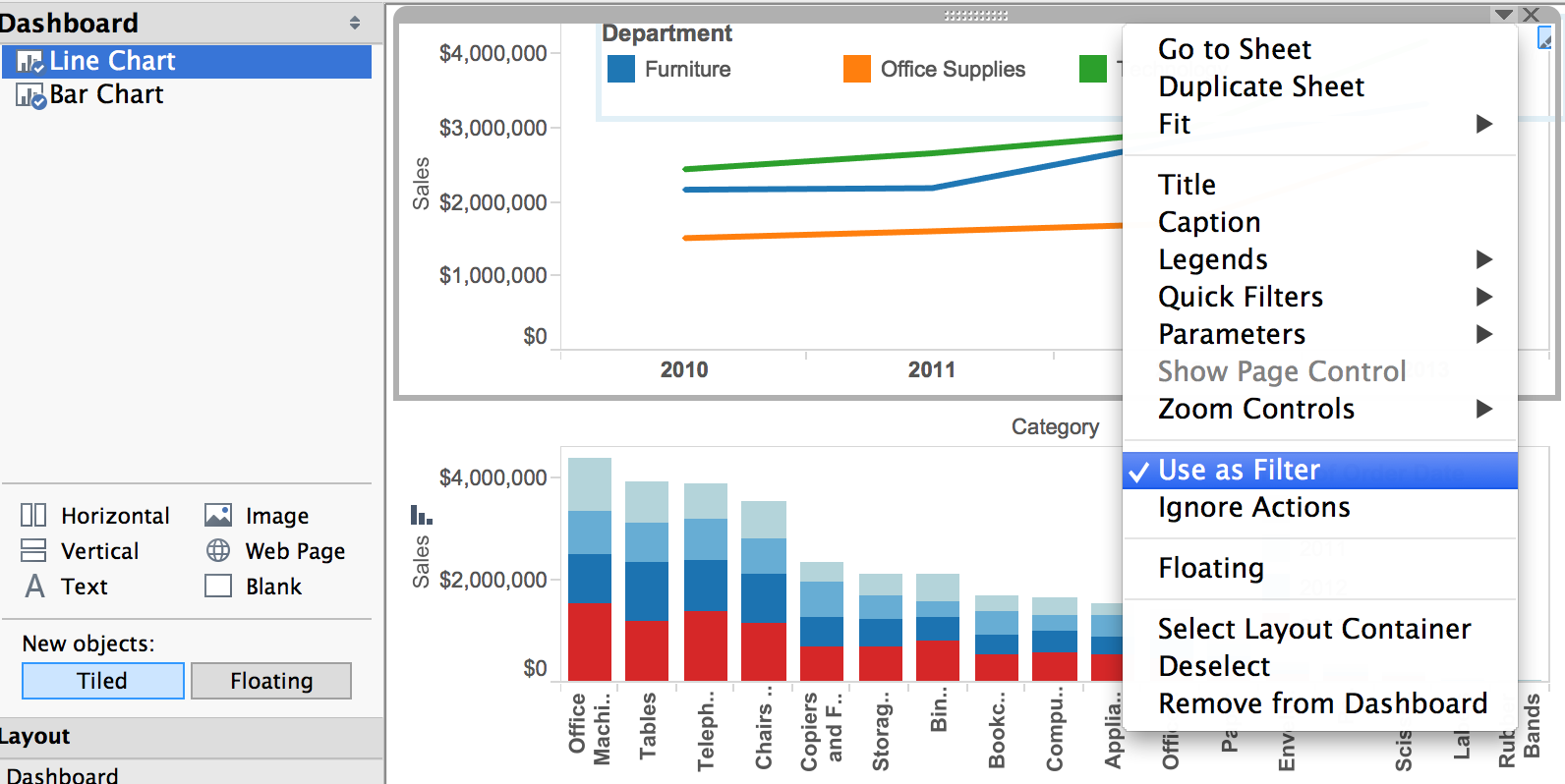





Method 2: Use the Dashboard Action menu




Use Case 2: Pre-Filtering a Large Table
Here's the use case for this one: You have a dashboard that includes a table, which you want there to be able to show some detail to users upon a filter choice. Easy, you can just show the whole table and then add a regular quick or dashboard filter right? But what if the unfiltered table is MASSIVE. It will probably take a long time to load via Tableau Server and people are going to get bored waiting for it.
So the thing to do is to have that table empty at first, and then to show the detail only when a filter choice is made. This will speed up the load time dramatically, especially on big data sources. Here's how you do it:
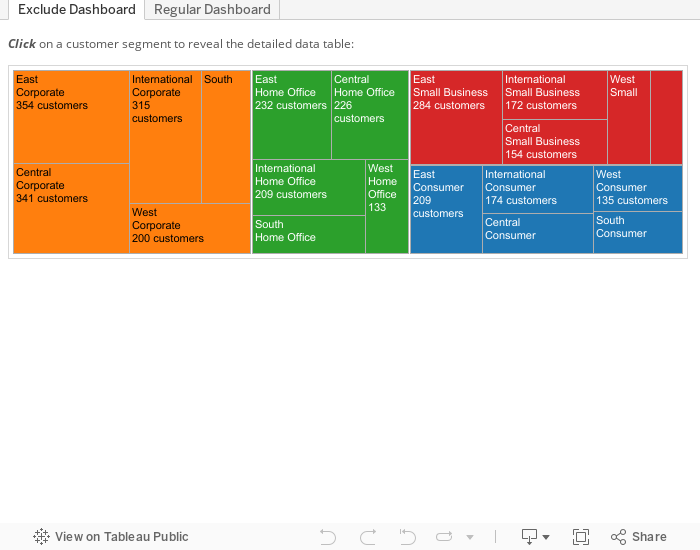
First off, create a dashboard including a table, here's a simple one showing customer numbers by region and segment in a treemap, and then customer details in a table:

Add in a filter dashboard action that looks like this, note the selection under 'Clearing the selection will'

At first nothing will look like it has changed. If you click on the treemap, it will filter as per normal. But when you click on the treemap in the same place again, clearing the selection, the table will clear completely and look like this:

See how there's nothing in the bottom segment? This is the time to publish the dashboard to Tableau Server so that when it loads in the browser, the load will be super fast. BUT, don't forget to add some instructions for your users in the title or in some text, like this:

Here's the 'exclude' version side by side with a regular filter. The data size here isn't massive so the load time won't be too different, but see what you think of the functionality.
Use Case 3: Creating a 'Cross-Blend' Filter
Data blending can be pretty cool, its a great way of bringing together disparate data sources and data types in Tableau without the need for any additional software or ETL work. It can also be a bit limiting to the functionality you can implement. One example of this restriction is Quick Filters. Its unfortunately not possible to add a quick filter from one data source that works on the different but blended data source. Try it, it probably won't work.
Tableau actually provide a pretty good explanation of how to deal with this problem here http://kb.tableausoftware.com/articles/knowledgebase/filter-data-sources but they left out one important detail.
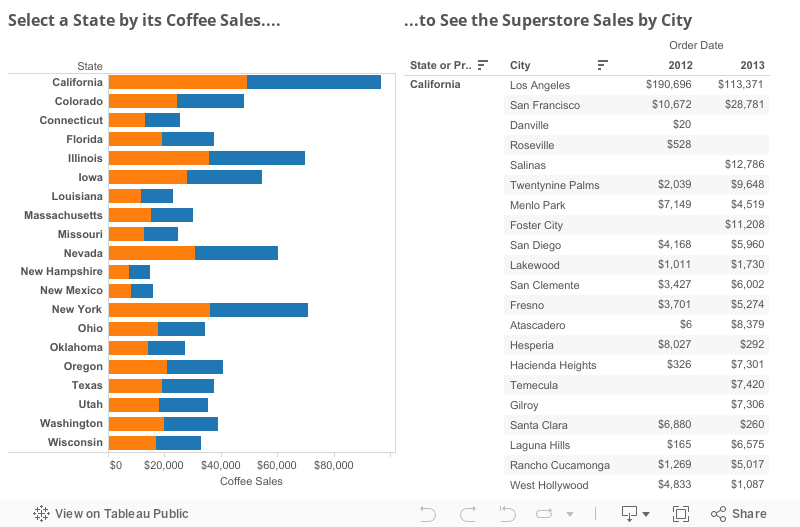
Take the dashboard below, showing coffee sales by state (from data source), and superstore sales by state and city (from another data source). And we want to allow the user to select a state in the left hand view to filter the state in the right hand view.

Data is blended on State = State or Province

So the filter action is set up as usual:

Now here's the important bit. If your blend field has the same name in both data sources, then using 'All Fields' will work. But if the field names are different it won't work, so you NEED to use 'Selected Fields' AND make sure you are pointing to the OTHER data source:


Use Case 4: Showing Images


Then create a URL dashboard action that points to a URL that contains a field name. For example http://en.wikipedia.org/wiki/<City> (more on this here).
Now this is great, but the downside is that most of the time, whole web pages look pretty crappy inside dashboards. Things get a bit squished and there are inevitable scroll bars. It can end up looking something like this:




http://i.cdn.turner.com/nba/nba/.element/img/2.0/sect/statscube/players… Name>_<Second Name>.png
Here's a little dashboard NBA player dashboard utilizing the URL action:

IMPORTANT NOTE - you can only have one of these type of objects per dashboard.
And here's another tip: be careful of size.
In Tableau Desktop, any URL picture will automatically resize to the size of the Web Page object you have inserted in the dashboard, like this:

See the tiny little Kevin Durant? BUT Tableau Server does not auto-resize the image, and so you will be left with an ill fitting picture that requires scrolling, like this:
An easy way to spot if this will happen is to, when in Tableau Desktop, hover over the image. If a magnifying glass with plus sign appears, its not going to fit. So resize your Web Object until no magnifying glass appears on hover. Bit of a pain this one and something I hope is fixed in later releases.
Use Case 5: Dynamic Text or Titles
That last use case, showing NBA players images, was pretty cool so I'm going to continue with it. Bt now I'll show how to also include the selected players name below the image.
Here's what to do:
Create a new sheet that includes just player names. Here's how you can set that up quickly - drop Player into Rows, drop it again into Text, un-show the header, delete the tooltip and get rid of shading and borders in formatting:


Then drop this new sheet into the dashboard in a small container, hide the title, format it to center align and get your font the right size, and set up a filter action that looks like this:

And you can of course do this multiple times to include different pieces of information in the text.
Use Case 6: Linking Out to Web Pages
Remember how I said in Use Case 5 that usually full web pages look crap inside dashboards? Well thankfully there is another option if you do want to link to a web page. This one is super simple, you create a URL action, but you don't include a Web Page object in the dashboard.
The only other consideration with this is how the action is triggered. In almost all cases you will want to use 'Run Action on Menu'.
Again, here's some NBA data with this action in play. Notice how when seen through server, the menu option is actually a hyperlink that pops up when you hover over a point to reveal the tooltip. Note also that the text in that hyperlink text is the same as the name you give the action:
One use for this I like to use is to jump to Google Streetview based on latitude and longitude data e.g. http://maps.google.com/?cbll=<latitude>,<longitude>&cbp=12,20.09,,0,5&layer=c
IMPORTANT NOTE: These actions don't mix well with actions driving URLs with web page objects. You can have either or, but not both.
Use Case 7: Highlighting and Labelling
This is a pretty neat trick. Say you have the following dashboard with a bar chart and a scatter plot (I'm sticking with my NBA data here). And you want to click on a player on the bar chart to see where they appear on the scatter plot:

Well what you don't want to do is just add a filter, or this happens!

well that's no good is it. So you can use a highlight action instead, but what if you add a highlight filter and select two players, which is which? In this case, which of these two centers highlighted in the scatter plot has the higher rebound rate? Anthony Davis or Dwight Howard?

Here's what you do. Go into the sheet that holds that scatter plot, add the Player field (or whatever field you are using to break up the detail of the scatter plot) to 'Label' on the marks card and choose 'Highlighted'. Now when you select some marks on that bar chart, the respective names show up on the scatter plot.


Easy right? I use that one a lot, for example to highlight the locations here.
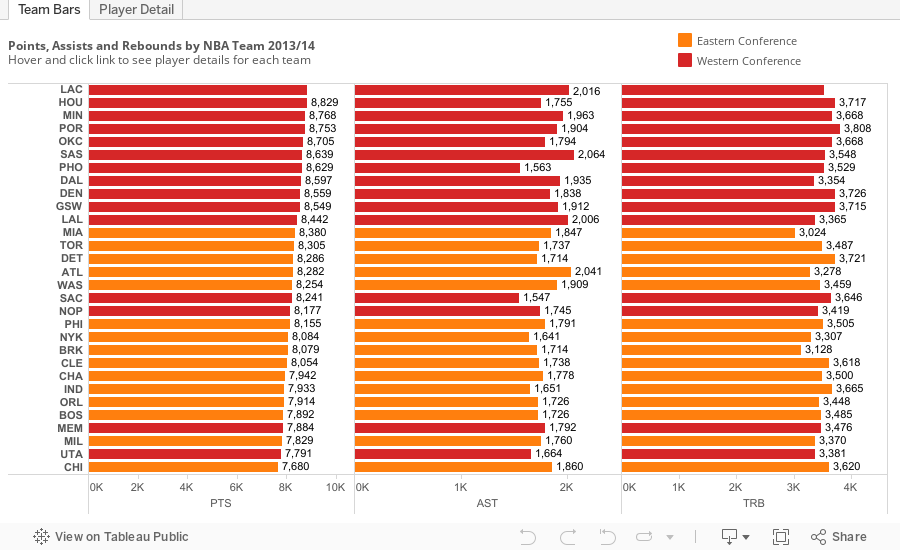
Use Case 8: Switching Dashboards
Dashboard actions can also be used to move between dashboards, either filtering data on the way, or simply moving from one to the next. I often utilise this functionality to offer users the option of moving from a chart heavy dashboard to a table based view which they may want to review in detail or export.
Here's how you set this up. Start making a 'Filter' dashboard action as per use case 1, but this time point to a DIFFERENT dashboard as the target sheet. There is a drop down that lets you pick the dashboard you are going to switch to (I chose 'Player Detail'). Again the Name becomes the hyperlink text if you use the Menu option, which I recommend.

In the case above I chose to filter on Team at the same time as switching dashboards, but if you use selected fields and don't pick one, the dashboard switch will occur without any extra filtering. Pretty neat!
If you are going to build in a field filter along with the dashboard switch, be careful as it can lead to some user confusion. For example if you have a quick filter on the target dashboard, be warned that quick filter is not going to reflect the selection you made with the dashboard to dashboard action. One way to get around this is to offer your users a 'show all' button they can hit to drop the existing action filter.
To do that, create a new work sheet which includes a single field, a calculated field that contains only text. Something like this:

Then bring that into the second dashboard and add a basic dashboard action, based on the field you filtered on, like so:

Because that field (in this case Team) doesn't exist in the 'show all' sheet, clicking the dashboard action will clear the filter, and any further clicks will have no effect. It will also reset the quick filter, which is handy!
Check out this all working below.
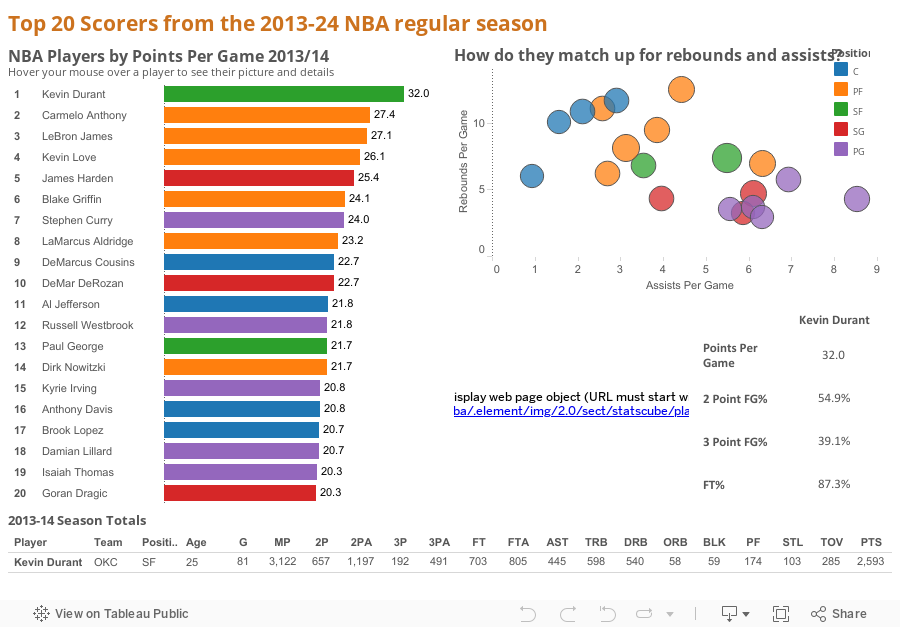
Use Case 9: Mixing Things Up
Ok so we've gone over a load of different action types and shown what can be done with them. The last thing I'm going to talk about is using multiple actions in the same viz. You can use as many actions as you want, and have different types of actions that are all driven from the same sheet. This can be really powerful when you are designing for interactivity. Some sheets you may want to filter, others to highlight and others still to show images, text or tables.
But be careful. Dashboard actions that conflict or do contradictory things will be very confusing, and just because you can add in loads of interactive functionality doesn't mean you should. Often times its best to keep things simple. Dashboard actions should add to the user experience, not detract from it.
Having said that, check out the viz below. Its a simple viz but there is quite a bit of interactivity delivered without the use of quick filters or parameters. There are 5 different hover driven dashboard actions built into this single viz, can you find them all?
{kind=link}
One final note. I discovered whilst putting this blog post together that the Safari web browser works way better with actions and images in Tableau Public than Google Chrome does.
Zugehörige Storys

Top 10 Qualifiers for Iron Viz 2025
 14 Januar, 2025
14 Januar, 2025

5 Ways to Use Tableau Public to Achieve Your Goals
 11 Januar, 2025
11 Januar, 2025

Shaping 2024 with Data: A Year of Data Visualizations on Tableau Public
 28 Dezember, 2024
28 Dezember, 2024
Blog abonnieren
Rufen Sie die neuesten Tableau-Updates in Ihrem Posteingang ab.